
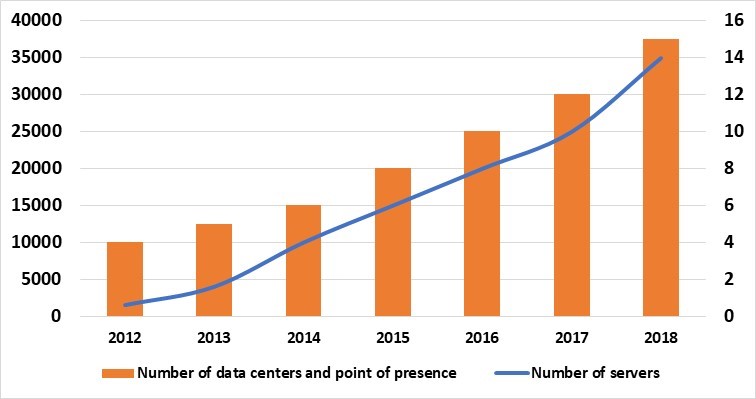
In Criteo, hypergrowth is something we have gotten used to. Our business has grown from a single data center in Paris back in 2005, to a globally distributed, multi data center infrastructure, with over 35 000 servers and what is one of the largest Hadoop clusters in Europe. This blogpost is the story of how we in the Criteo Infrastructure team have changed to allow us to react quickly to the ever-increasing needs of our business.
Back in the day….
Back in the beginning, in 2005, all Criteo’s services were handled by just a bunch of servers in a single data center in Paris. As the business grew we added a second data center in Amsterdam for load balancing and to provide some level of redundancy. We started our first US data center on the east coast, followed afterwards by a second on the west coast, to handle the latency caused by the large distances involved in serving such a huge area. We had our first Asian data center in Tokyo, followed afterwards by another in Hong Kong and a 1000 node Hadoop dedicated cluster in Europe…
Each location started with just a few racks of servers, installed in cages in the leased data center space. Scaling the clusters could easily done by adding more servers and additional racks. Servers were ordered and unpacked within each data center. Racking, cabling, powering them took few weeks. We always made sure that additional servers were always ready for unexpected load.

Resources were ready for any unexpected event and the infrastructure was ready to face any challenge. Our advertising product was very successful, plenty of new customers were added to the platform and the business kept growing
The architecture scaled so quickly, with so much change that a dedicated Escalation team was required to tackle any critical incident. They act as the software firemen, coordinating teams around them to fix issues. When facing load issues, the Escalation team requests additional servers from the stock. Every year, the Black Friday period generates a huge load on our infrastructure, but it is not an issue thanks to our hardware capacity.
As the resources needed by the business was increasing, the infrastructure scaled up: first more servers were added in a few racks, then servers were ordered by racks of 24, then by 48, and eventually by full room. In the meantime, the 3-tier architecture had evolved to a more robust architecture, including technologies such as NoSQL, Hadoop and Mesos.
The measure for scaling up became the quantity of megawatts provided by a data center. Hardware selection is chosen based on number of CPU per m2, CPU per available storage Tera octets, power consumption and cost.
Cloud vs Self Hosted
For Criteo, hosting our servers is cheaper than going to the cloud. Whilst a start-up could choose to start with hosting their infrastructure in the cloud, due to the low up-front initial investment, at Criteo we choose to host our own servers. We chose to do this as the ongoing costs of cloud infrastructure exceed those of own hosted hardware once you go past a few hundred servers. For Criteo, the investment in a server will have paid for itself after two years. After that, we only incur the monthly running costs for rent, cooling and power. After three year the hardware can be depreciated, and new hardware version can be rolled out.
The Need for Speed
As the business continues to grow, we realised that we had to ramp up our data centers much more quickly. Our servers are now delivered cabled within their racks by providers to the data center. Those fully populated racks are delivered in a ‘plug and ready’ mode for power and network. This represents a logistic challenge: each rack contains network switches, 25 to 45 servers and weight up to 1.2 Tons. Trucks deliver them by groups of 20…
The time when Criteo was a small company is gone.

As uptime is critically important for our business and our clients, we need to plan for the all the peaks and troughs of the year. In advertising, the busiest time of the year is around the Black Friday shopping event. To prevent any risks raised by the associated high traffic rate increase, we need to anticipate as much as one year before. A traffic forecast is applied to application performance and dependencies. The required bandwidth and server quantities are estimated and purchased for our data centers. We have learned from experience that such anticipation is critical, and the yearly budget takes this point into account. The budget allocated to infrastructure changed from a percent of revenue to a complex exercise reviewing all running cost and forecasted needs.
No one wants to end up in a situation where input bandwidth, frontend or databases masters are heavily overloaded and not able to sustain incoming traffic without any available resources left.
Anticipation is key!
In September 2017, we created a dedicated team, known as Qapla (from the Klingon word for success), to tackle this Capacity Planning challenge. The team mission is fascinating; to continue to scale the Criteo infrastructure bigger and faster. Criteo has over 35 000 servers worldwide, a Hadoop cluster of 171 PB and 42 000 cores. It’s already BIG and will only get BIGGER (up-to-date details are listed here)
The team communicates with all R&D functions (developers, devops, infrastructures, network, finances and team leader), and brings together different profiles, mixing Analytics, Devops, Research, Finance and Product profiles.
The focus of the past year was on anticipation, by aiming at:
- Forecasting and building our yearly budget plan for infrastructure
- Supporting new projects & products so that they can scale quickly and globally, without hiccups
- Building long term predictions on our hardware needs to provide guidance
- Sizing Criteo clusters (Hadoop, Vertica)
- Building robust monitoring with persisted capacity usage data
- Identifying the best locations for future data centers
- Optimize resources allocation and improve application footprint
- Evaluate and measure new hardware performance
As Criteo is scaling up, the capacity planning team is growing, and we are looking for talents to overcome our future challenges:
- Evolve the server ramp up process to handle stream deployment instead of batches
- Improve the data we store on all our assets for capacity planning (asset life cycle, hardware issue statistics ..)
- Planning an upgrade strategy for tens of thousands of servers
- Study geographic service coverage for future data center locations
If you are interested by these or any of the other challenges faced by the R&D teams at Criteo then please feel free to check the available roles at https://labs.criteo.com/rd-jobs/
Post written by:
 Pierre-Yves Verdon Senior Hosting Engineer, R&D. |
-
CriteoLabs

Our lovely Community Manager / Event Manager is updating you about what's happening at Criteo Labs.
See DevOps Engineer roles

