
In this blog post we will summarize our experience at Kafka Summit London and highlight the key takeaways of our favorite talks regarding Kafka pipeline and streaming processing. If you are interested in Kafka ops and monitoring, refer to the second part of this post.
What is Kafka?
Apache Kafka is a distributed message queue initially developed at LinkedIn and open sourced in 2011. Kafka is designed to offer a high-throughput, fault tolerant, and scalable messaging system. Nowadays, with technologies like Kafka Connect, Kafka Stream, or KSQL, Kafka is not just a message queue but a complete ecosystem to create an enterprise-scale data streaming platform, addressing problematics like data pipeline, micro-services bus or stream processing.
Kafka Summit London 2018
After Kafka Summits 2016 and 2017 which took place in the USA, Kafka Summit London 2018 was the first European edition of the conference. As such, it was a great opportunity for us to meet many people from a wide range of companies, from small companies presenting their Kafka use cases to the biggest, like IBM, who provides Kafka as a service for their customers.
Confluent, the company behind Kafka and one of its biggest contributors, was the organizer of the event. Their main product is a Kafka distribution called Confluent Platform, built on their vision of Kafka as a streaming data platform.
Criteo was a sponsor of the Kafka Summit London 2018.
Kafka @ Criteo
Criteo’s first Kafka cluster was deployed 4.5 years ago to prototype a streaming application with Storm. Three years ago, it replaced our whole business logging pipeline to feed data into our centralized data lake. Today, we are using several streaming frameworks for our data workflows and for replication, namely Kafka Connect, Kafka Stream, and Flink.
As streaming is growing fast to reduce latency compared to batching, we expect to double our Kafka infrastructure in the coming months.
Some key figures on Kafka at Criteo:
- Up to 6M+ messages/second (400 billion messages/day)
- 150+TB/day
- 250+ Kafka brokers on 6 datacenters
- 150+ topics
- 4000+ partitions / cluster
For more details, you can have a look at our teammate Oleksandr Kaidannik’s talk, about the challenges we face running such infrastructure at scale.
Keynotes insights
During its Keynote, Audi used a quote that we found particularly accurate: “life does not happen in batch mode.” It’s interesting and not so common to see a Keynote from a car manufacturer in a software-oriented conference, although it makes senses once you understand that collecting data from their connected cars is key to exploring new business opportunities. Kafka and its ecosystem were the choice to make their vision possible.
The keynote from Jay Kreps, one of the creators of Kafka and CEO of Confluent, demonstrates why he thinks that Kafka is so different from other messaging systems such as ActiveMQ or RabbitMQ: with Kafka, you do not deal with messages but with an event stream. Kafka and its ecosystem tools are designed to allow you to build scalable and stateful streaming applications. Your applications no longer need to deal with a message bus on one side and multiple databases on another side to maintain states. For example, using only Kafka and tools like Kafka Connect and Kafka Streaming, you can stream entire databases changes into Kafka, maintain a scalable and fault tolerant state of this event stream in memory (KTable), and use this state to enrich and react in a streaming way to any kind of event you receive.
Next on the program was the keynote from Martin Fowler and Toby Clemson. They presented the design of a real event-based banking architecture, which was a great example of how you can put this approach to practice.
Last but not least, the Keynote from Neha Narkhede, co-creator of Kafka and CTO of Confluent, gave us a glimpse of a possible future Kafka feature called Global Kafka. Currently, Kafka has no native cross-cluster replication feature. Some external tools exist to do that, but they can be tricky to set up and they do not provide the ability to automatically switch your Kafka client from one cluster to another. If Global Kafka ever becomes reality – currently it is just a vision and not on the official roadmap – it will be an exciting feature that may be the answer to complex problematics (Kafka cluster synchronization across datacenters for scalability or disaster recovery plan purposes, for example).

Create data pipeline with Kafka
Distributed Data Quality – Technical Solutions for Organizational Scaling – Justin Cunningham – Yelp
Yelp was an early adopter of Kafka. At that time, Confluent did not exist, nor did Schema Registry. In the SOA era, teams are responsible for their own services, but how can you make sure that your infrastructure stays consistent as a whole?
Your data is your API. How can you make sure to not break it for your clients?
The first try at documenting columns of their Data Warehouse was to use a giant shared Excel file. It worked for some time but was not scaling well with the increasing number of services and data sources. Nevertheless, it was the first step to discovery and ownership.
Then, they created some tools to manipulate, register and update schemas and required developers to describe every single field.
By collecting metadata from their ETL pipelines, they built a global dependency graph and data lineage. A central schema and metadata registry facilitates dataset monitoring and metrology. Now they can quickly spot the origin of any processing lag.
Concerning Kafka, they monitor offset and time delay. A particular dataset might have some time lag without having offset lag.
At Criteo, we experienced similar scalability issues. Today we have more than 450 services running in production. Data schema is the contract between teams and we had to ensure that updates would not break existing software. Our streaming usage is growing but our main ETL is still running on Hadoop, so we focused our effort on Hadoop ETL first. It enabled us to migrate from JSON to a more efficient format such as Protobuf. It reduced storage costs and network bandwidth usage and increased data quality guarantees.
Look Ma, no Code! Building Streaming Data Pipelines with Apache Kafka and KSQL – Robin Moffatt
You are now convinced. You want to create a streaming data platform with Kafka to unify your events from different sources. You may think you will need to deep dive into software engineering and especially Java development, which is true, and which is what we did and still do in Criteo to run our Kafka platform.
However, with the Kafka ecosystem latest tools, there is a way other than coding: use Kafka Connect with already available connectors to ingest data from external systems and KSQL to query Kafka data with SQL and streaming. Since a demo says more than slides, half of the presentation was hands-on. Robin accepted the challenge and succeeded to “live configure” a non-trivial data pipeline (database ingestion with MySQL CDC connector, some streaming aggregation and joins with KSQL) in less than 30 minutes! In the end, the built pipeline is fully scalable and can be production-ready if you invest some time to integrate it into your monitoring and continuous integration infrastructure (but here you might need to do some code!).
Stream processing with Kafka
Stephan Ewen, co-founder and CTO of Data Artisans, the company behind Flink, introduced the technology. At Criteo, we already use Flink for streaming processing in production, but it is always interesting to see how the tool is evolving.
Flink is an open-source framework for distributed stream processing. It has many features that distinguish it from its competitors:
- Flink can be deployed standalone or with resource managers such as YARN (Hadoop), Mesos, or Kubernetes;
- It is commonly used with Kafka, as the underlying storage layer, but it is not limited to it, and can consume or produce data to and from databases, filesystems or other types of resources;
- Sub-second latency that can be as low as few 10s of milliseconds;
- Guaranteed exactly once semantics for application state;
- Guaranteed exactly once end-to-end delivery with some sources and sinks (Kafka to HDFS or Cassandra);
- Support for event time (the timestamp usually inside the message record);
- Lightweight checkpointing mechanism;
- Re-processing via save points;
- Batch processing API;
- High level APIs such as CEP (for Complex Event Processing), SQL and Table (for structured streams and tables), FlinkML (for Machine Learning), and Gelly (for graph processing)
Flink at Criteo
We run Flink over a Yarn cluster and use HDFS as back-end storage for the state. We started using Flink in 2017 and we still have only few teams that started using it. The main pattern is to consume data from Kafka and store them on HDFS or back to Kafka. We process around 100 k messages per second, which is still far from our scale of millions of messages per second for some topics. The first use-case which introduced Flink at Criteo is near-time revenue monitoring. We compute revenue as a streaming job and for some period with historical data in order to find any signal of anomalies. Currently, we are working on the rule engine on top of Flink SQL for realtime data analysis.
KSQL 201: A Deep Dive into Query Processing – Hojjat Jafarpour – Confluent
The talk was handled by Hojjat Jafarpour, the project lead of KSQL at Confluent. As mentioned in Robin Moffatt’s talk, KSQL is one of the key new features of Kafka and makes it possible to build streaming jobs using just SQL. It gives a lot of power to the users, especially those who do not have deep knowledge of coding or the Kafka Stream API. Here at Criteo we are not using KSQL yet, but we are excited to do our first tests.
Kafka ecosystem provides you 3 ways to deal with stream processing
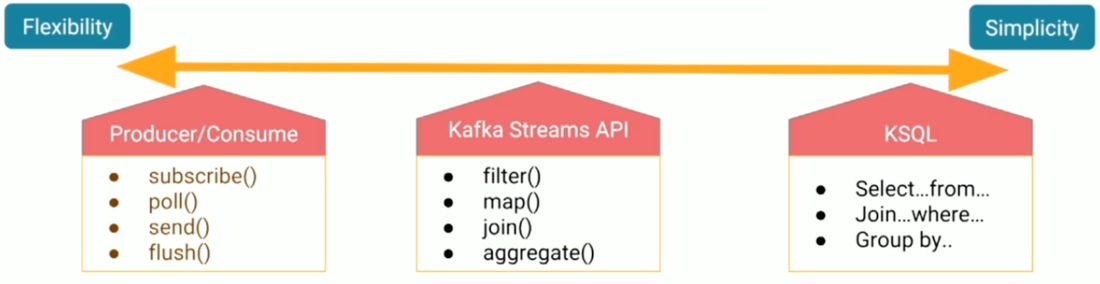
- Kafka Producer/Consumer
This is the lower level API, where the user (a developer) connects to Kafka brokers using an API that basically retrieves messages as records. All the data manipulation, when the messages get out of the brokers, isthe responsibility of the developer. This is lightweight, but very low-level data manipulation. - Kafka Streams
This is a Java library that brings much more functionality to the user when reading and writing from and to Kafka. It’s possible to build applications that aggregate data by a time-based window and store state efficiently. You can build a highly scalable, elastic, fault-tolerant, distributed real-time application on top of your Kafka architecture. It has many built-in primitives like filter, join, map, groupBy, count etc. - KSQL
It’s a SQL implementation that brings all the power of Kafka Streams but in a much simpler way. You use SQL statements to create continuous streams of data or tables.
To use KSQL you need to start a KSQL Server. It is a plain java application that runs with or without a cluster system (like Mesos). It can run in interactive mode or long-running mode.
The KSQL Engine is responsible for executing KSQL statements. There are 2 types of statements:
- DDL (Data Definition Language): CREATE STREAM, CREATE TABLE, DROP STREAM …
- DML (Data Manipulation Language): CREATE STREAM AS SELECT, CREATE TABLE AS SELECT and SELECT
Each of the KSQL Server instances has an in-memory Metastore, used to manage the streams or tables that are being processed (columns, types, sources etc).
As any other regular relational database, KSQL Engine first parses the statement, then creates an abstract representation of the statement as a tree (AST), and ultimately creates a plan that is translated to the API primitives (select, groupBy, aggregate etc).
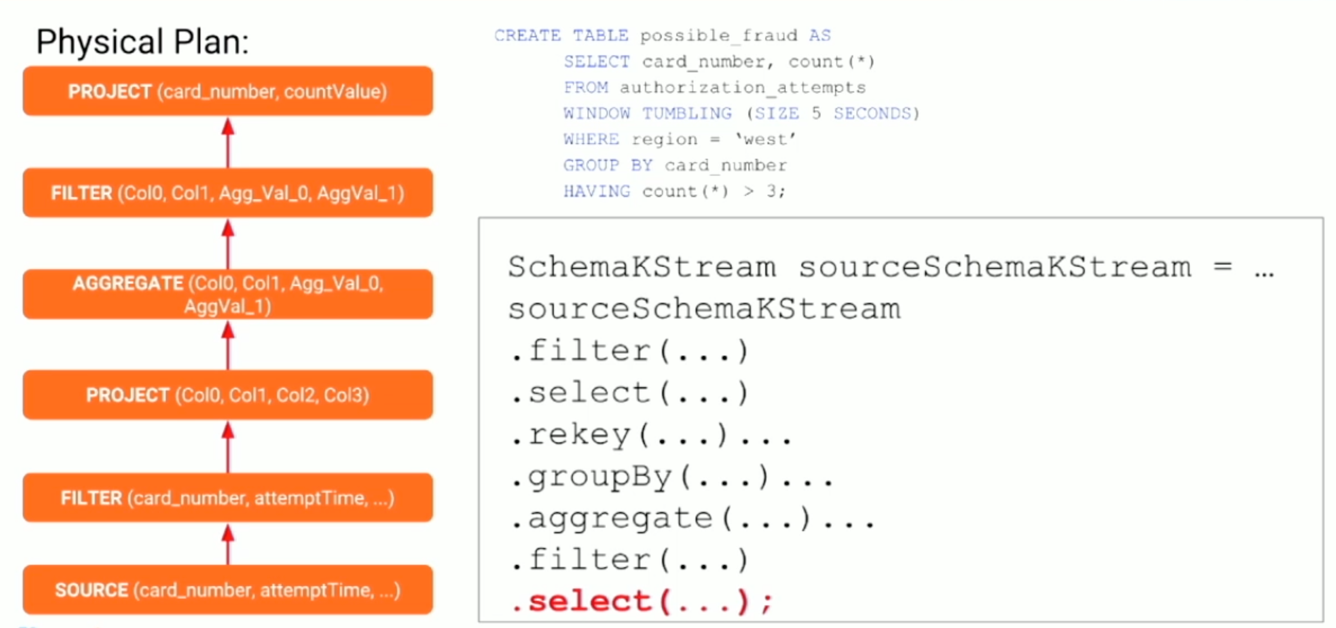
Remarks:
- KSQL supports 3 types of formats: Json, Avro (using Schema Registry), and delimited;
- It only supports flat types for now, but they are working to support nested types (e.g. address.state);
- It doesn’t support Stream-Stream joins yet, but it is possible to do Stream-Table joins;
- There is no fine-grain authorization for the KSQL. The authorization is given on the KSQL Server level;
- It’s not possible to call KSQL from Kafka Stream yet – as Spark does, for example.
- There is no way to change the schema yet. If the schema changes, you need to recreate the stream running the statement again.
Here you can read the second part of this post, where we summarize the talks regarding Kafka ops and monitoring at the Kafka Summit London 2018.
Post written by:
 |
| Mathieu Chataigner – Staff DevOps Engineer Hervé Rivière – Snr DevOps Engineer Ricardo Paiva – DevOps Engineer |
-
CriteoLabs

Our lovely Community Manager / Event Manager is updating you about what's happening at Criteo Labs.
See DevOps Engineer roles

