
Prerequisite:
A basic understanding of Spark and MapReduce big-data processing framework.
Please refer to Blog Post: Spark Custom Partitioner to get a detailed explanation of the business problem.
Introduction
This blog covers shared variables in Spark. Our enrichment workflow is running on MapReduce. Among other reasons, we are moving to Spark to handle faster enrichments with less memory and CPU resources. Not surprisingly, there was a need to reuse MapReduce components like counter data-structures and enrichment processor-set and framework. We were able to reuse these components with creative object-oriented abstraction/wrapping around Mapper.Context, Reducer.Context and SparkContext and ‘dependency injection’.
Our ML model’s size is 500MB. We needed a way to effectively load this model in a distributed environment.
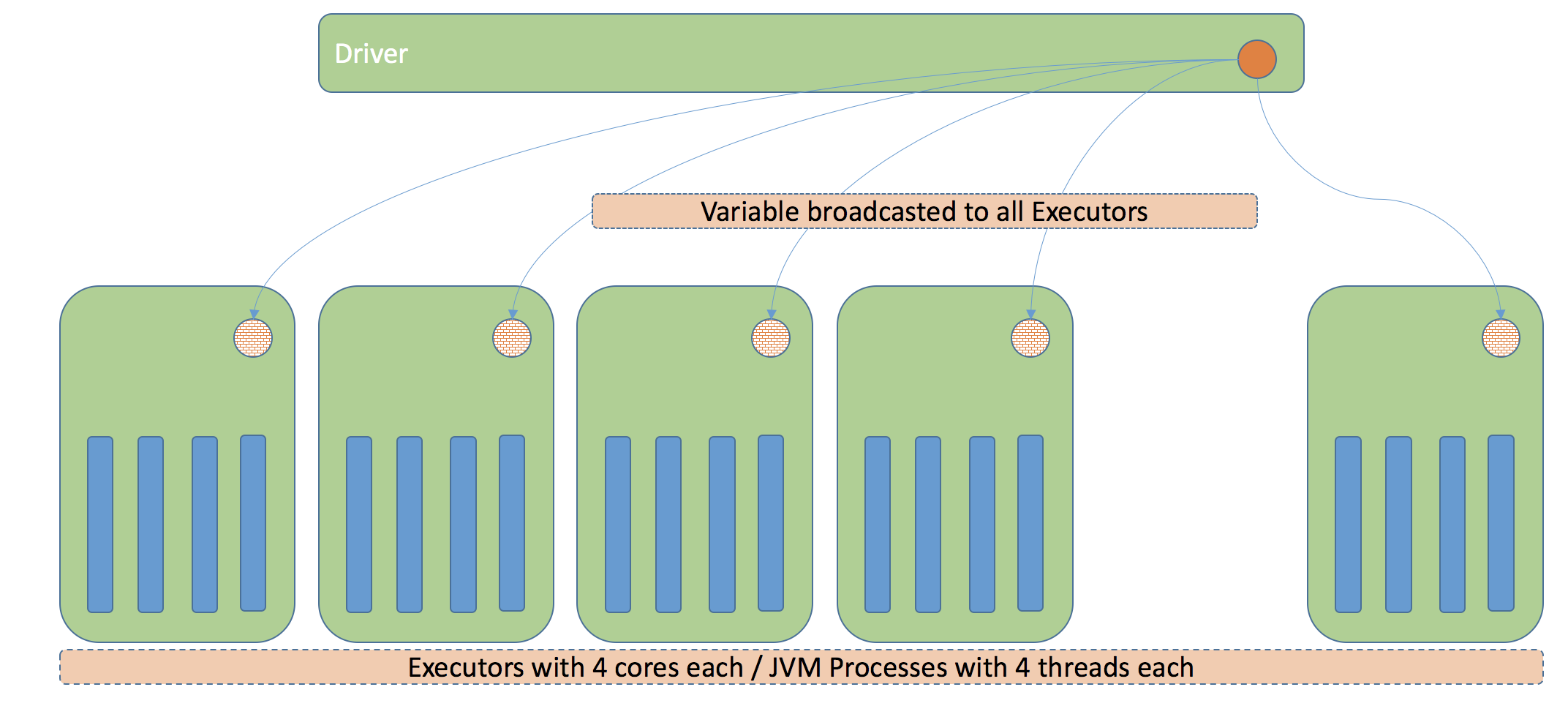
Broadcast Variables: Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. They can be used, for example, to give every node a copy of a large input dataset in an efficient manner. Due to requirement of reusing MapReduce components, we have to broadcast the whole enrichment-processors set. Which means it needs to be serializable. The object graph is complex(with third-party library) and includes a lot of classes making this task practically impossible.
RDD Transformations – map vs mapPartition: map applies the function being utilized at a per element level while mapPartitions applies the function at the partition level. Sometimes you might have a need for heavyweight initialization that should be done once for many RDD elements rather than once per RDD element. Initializations such as creation of objects from a third-party library cannot be serialized so that Spark can transmit it across the cluster to the worker nodes as a broadcast-variable. In this case it makes sense to use mapPartitions instead of map. mapPartitions provides for the initialization to be done once per worker task/partition instead of once per RDD data element.
This is good progress, but we realized we were loading a 500MB model to enrich 50-75MB zipped products (150-300 MB unzipped). It still seemed ineffective usage of executor resources. For DB connection init case, mapPartition solves the problem of fixed-cost associated with creating a connection and keeping the no. of DB connections manageable. However, loading a ML model introduces following problems.
- Time to load
- Higher memory footprint
- Frequent and/or longer GC pauses.
So, we can’t use broadcast variables and loading ML model per partition is still ineffective usage of resources. Singleton pattern to the rescue! In essence, sharing variables between tasks/partitions within the same executor. Executor is a JVM process with configurable no. of threads (spark.executor.cores) working in parallel. Since, we were reusing the MapReduce processors, we were loading the model for each partition. So, for 6000 partitions with 200 executors, we were loading the model 6000 times (30 times in each executor). Refer to this page to get insights into how sub-tasks handling differs between Spark and MapReduce. Making the model loading singleton brought down the Spark stage processing time for above use-case from 50 to 20 mins.

Post written by :

Pravin Boddu
Senior Software Engineer – Palo Alto
-
CriteoLabs

Our lovely Community Manager / Event Manager is updating you about what's happening at Criteo Labs.
See DevOps Engineer roles

