
Prerequisite: A basic understanding of Spark big-data processing framework.
Introduction
Criteo strategically places our retail partner’s product ads on publishers like CNN and NyTimes. Criteo Products make this possible by using internally enriched versions of catalog products from our retail advertisers(partners). Enrichment workflow utilizes ML to provide additional insights into our partners’ product catalogs by
- Categorizing products into Google’s product taxonomy categories. e.g. ascertain that Product A from Walmart and Product B from Sears are both Smartphones.
- Adding extra brand fields by identifying product’s brand from title and description. e.g. ascertain that Product A from Walmart and Product B from Sears are both a Samsung.
- Clustering similar products together to improve upon recommendation/attribution. (Enrichment workflow only assigns unique ID to similar products. Identification of similar products is done by a separate job). e.g. Find that Product A from Walmart and Product B from Sears are both a ‘Samsung Galaxy S8 – Midnight – Unlocked – 64 GB’
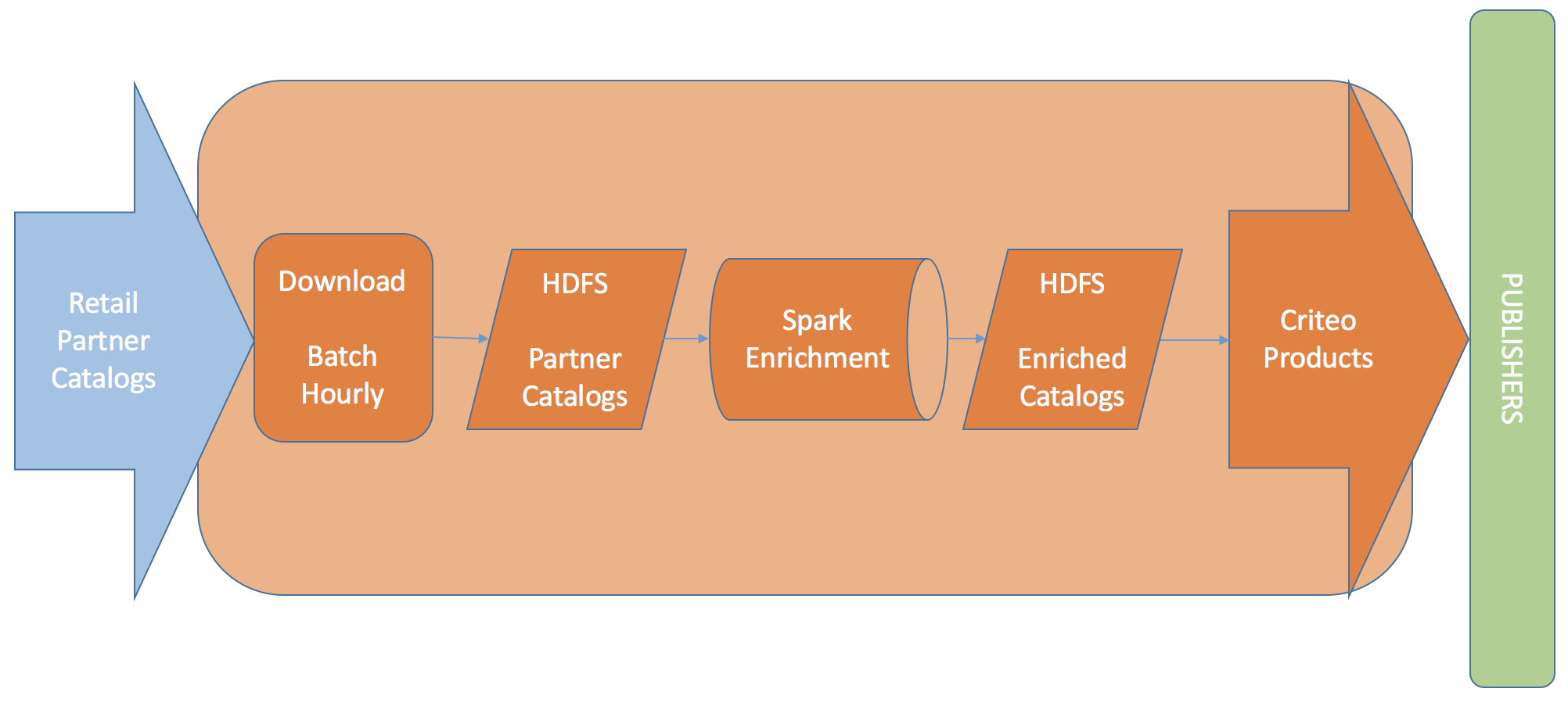
Enrichment pipeline receives product catalogs from over 17000 retail partners enriching more than billion products every day. Present implementation is in Map/Reduce. Spark being one of most popular distributed big-data framework, we wanted to explore it to get better resource utilization, performance and programming API.
Challenges
Catalog Processing: With every batch processing, we need to process up to 1000 partner catalogs so we can update catalog on time for downstream jobs in Criteo.
Data Skew: We enrich partner catalogs in hourly batches. Partner’s catalog sizes vary substantially. Depending on the batch hour the number of catalogs and their sizes can be really different.
Partitions segregated by partners: This will make sure we can save enriched products in partner specific directories. Also, in future we might have to use geographical-market or partner specific ML model.
Fault Tolerance: Any failed processing for a catalog should not fail whole batch job.
We explored two solutions. One is to run multiple spark jobs under the same spark context concurrently, each job handling one catalog only. Another one is to run one spark job for all catalogs in the batch.
Separate Job Per Partner Catalog
Inside a given Spark application (SparkContext instance), multiple jobs can run simultaneously if they were submitted from separate threads. In this implementation, we try to leverage this mechanism.
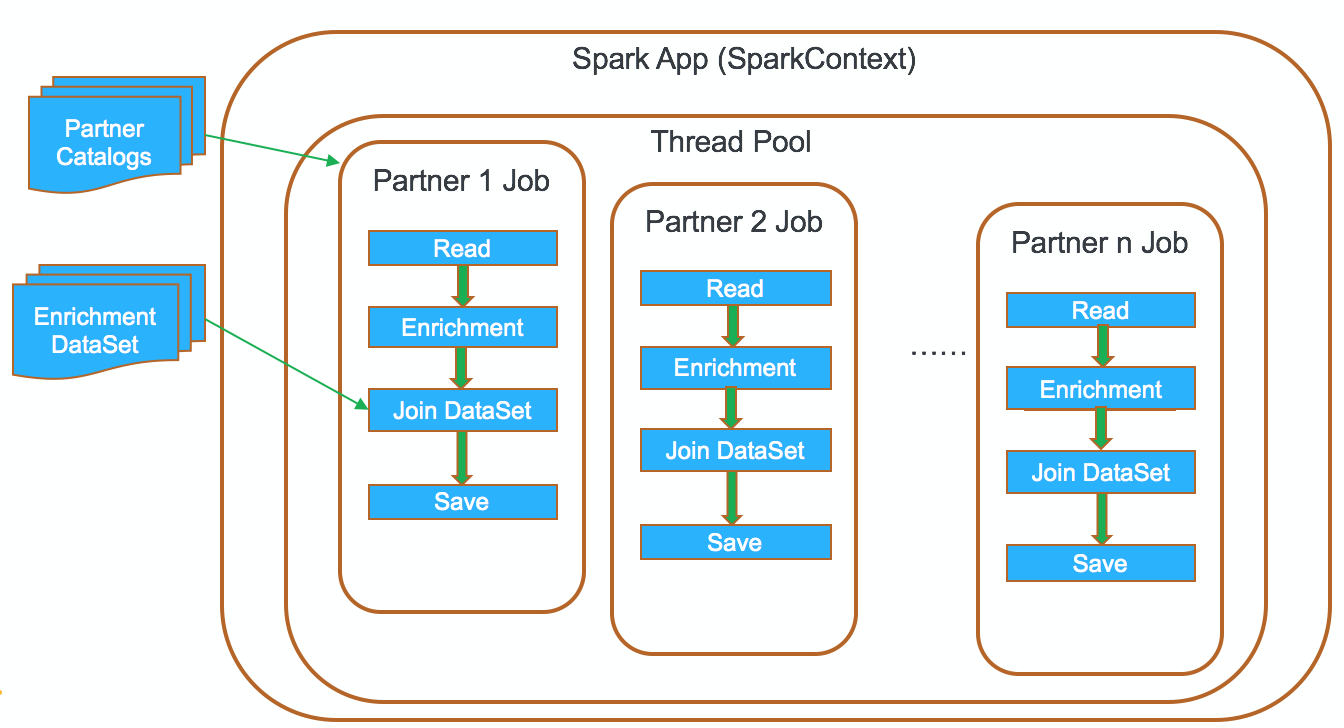
We launch a spark job for each catalog in a separate thread. The driver job threads will share the same thread pool, Spark jobs and tasks will share allocated executors on the cluster. In this design, failure of one catalog processing will not spread to other catalogs. Error handling logic is very clean. Any exceptions during enrichment including cluster issues can be easily captured by following code.
Things started going south when we tried to optimize performance. In order to run spark jobs in parallel, we needed to do thread management so we can manage proper throughput. In essence, we were reinventing the task management which Spark inherently provides. During enrichment, we need to join with another RDD for clustering similar products. We have to reload it in every job because there is no way to share the RDD across jobs. There are technologies like Apache Ignite which supports sharing RDD, but it will complicate our tech stack. We also explored partitioning enrichment dataset at partner level. We realized we were trading cleaner error handling logic with complicated resource management logic which is already built in to spark.
One Job for All Partner Catalogs
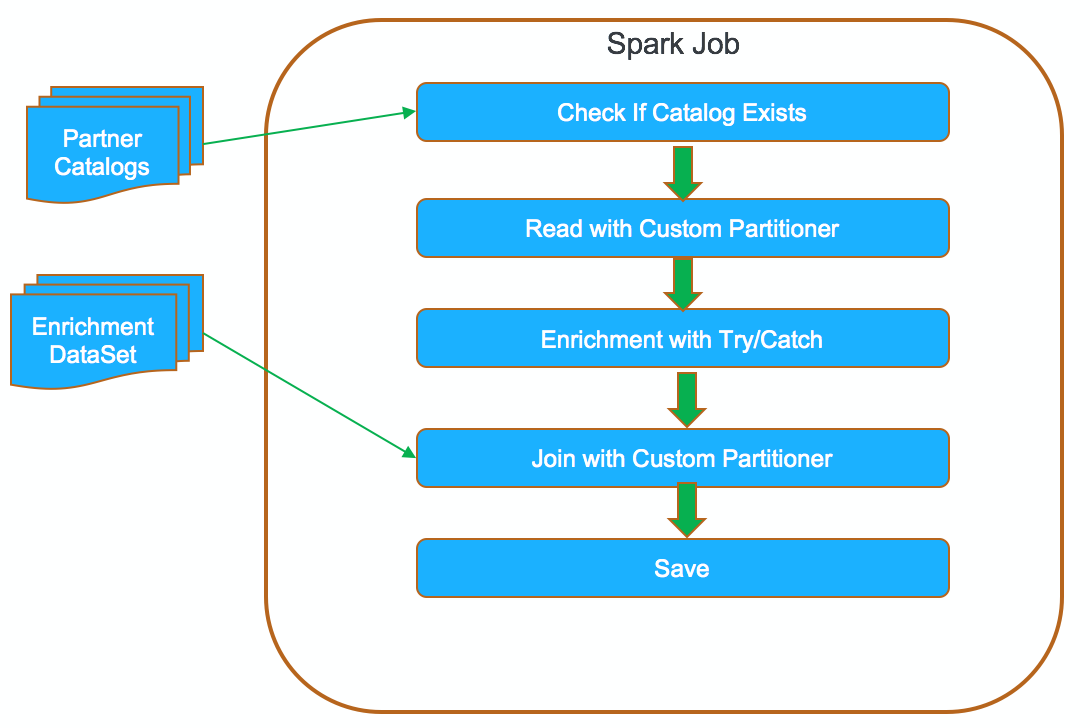
This approach is the standard one RDD spark implementation. Addressing data-skew with this approach posed a challenge. With separate-job approach the whole RDD belongs to a single partner. A simple coalesce with shuffle will spread the products across available cluster resources for faster processing. With the single-job approach, the products will get spread across the cluster, but the partitions will have commingled partners’ products. We implemented a custom partitioner to make sure the products are segregated by partner during the shuffle. You can find more detail on the custom partitioner here. In addition, custom partitioner lets us track partners’ success/failure status and keep the RDD from getting shuffled again during a join operation with an enrichment dataset. With one job approach, the downside is that you have to pay attention to catch any possible exceptions.
Implementation Comparison
With two different implementations, we summarized pros/cons as following

Performance tuning is a very important part of spark implementation. With all the config ‘knobs’ that Spark provides for performance tuning, it was a challenge to tune a one job Spark application. Trying to tune a N jobs application was adding to the challenge exponentially. On the other hand, our cluster was very stable to cause failures to our jobs. Also, retrying the whole Spark application and using smaller partner batches solved the error handling scenario for one-job case. Given these findings, we choose to go with one job for all partners solution.
Summary
Although Spark supports multiple jobs under same spark context, we have to be very careful as it may add additional complexity. It should be only used as a last resort. We recommend designing your Spark application as N applications with one job instead of one Spark application with N jobs.
Here are some other interesting articles covering innovations to challenges we encountered during the project.
Blog Post: Spark Custom Partitioner
Blog Post: Intra-Executor Shared Variables
Post written by :
 |
 |
| Pravin Boddu Senior Software Engineer – Palo Alto |
Xiaofeng Wu Senior Software Engineer – Palo Alto |
-
CriteoLabs

Our lovely Community Manager / Event Manager is updating you about what's happening at Criteo Labs.
See DevOps Engineer roles

