
Several months ago we announced the availability of a larger version of a dataset that we released for the Kaggle click prediction challenge.
We are now very pleased to report that it is currently used by an exciting Edx course about Machine Learning at Scale using Spark and Python (esp. PySpark).
During one of the five labs of this course, you will use our dataset to understand the various techniques involved and build a fully working Click-through Rate Prediction Pipeline.
Among other things, you will learn how to:
- extract different types of data (numerical and categorical) using one-hot encoding or feature hashing (for dimensionality reduction);
- code gradient descent, various loss functions and regression algorithms;
- use state of the art libs (MLlib) to train models;
- optimize models via hyper-parameter tuning using grid search;
- interpret the probabilistic classifier via a ROC plot.
It is not allowed to post solution examples of the course, but you will find below some real illustrations from the lab.
More than 47.000 students have already enrolled in this course. Will you be one of them?
Happy coding!
Illustrations :
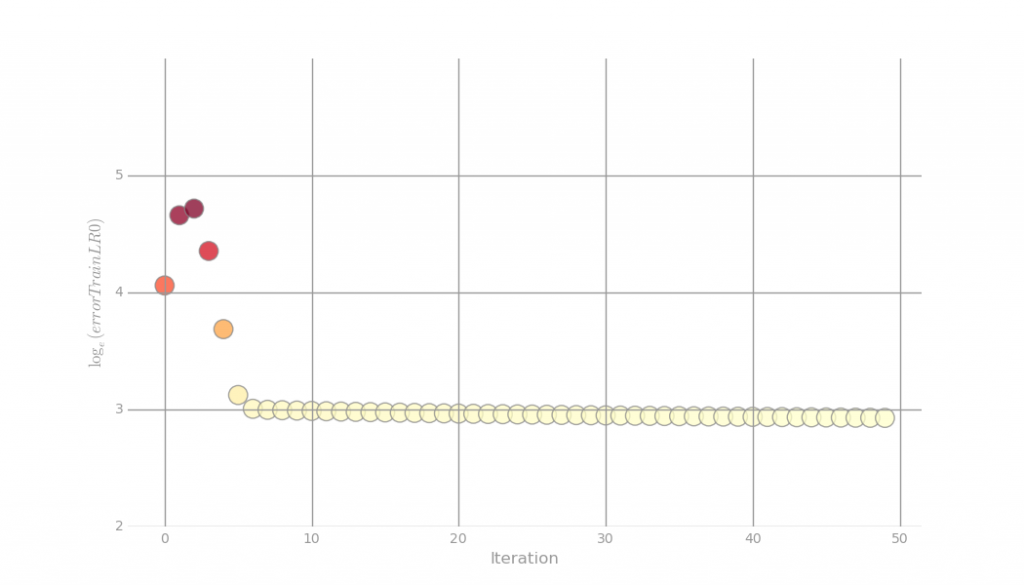
Fig 1. – Loss of linear regression during iterations of gradient descent
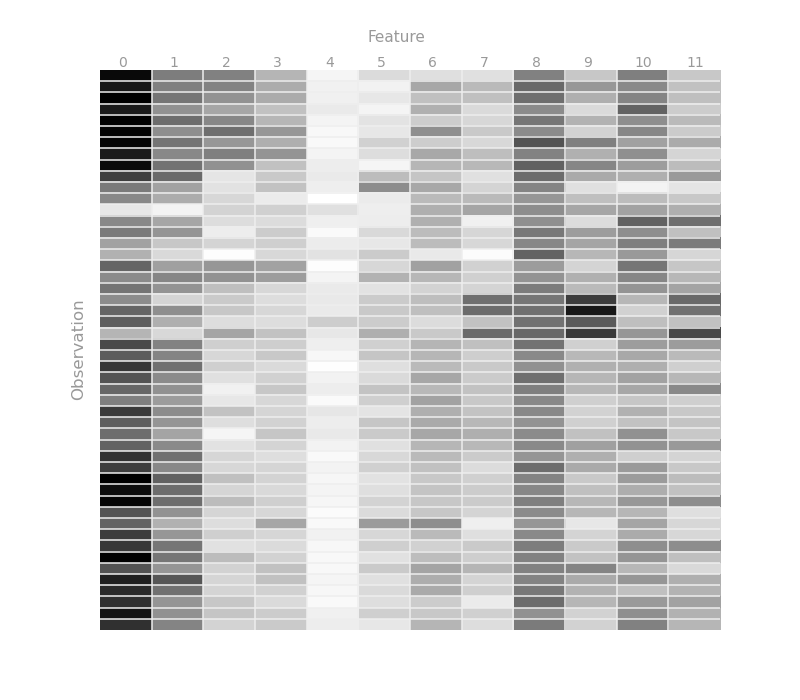
Fig 2. – Features modalities accross observations

Fig 3. – ROC plot true positive / false positive with varying threshold
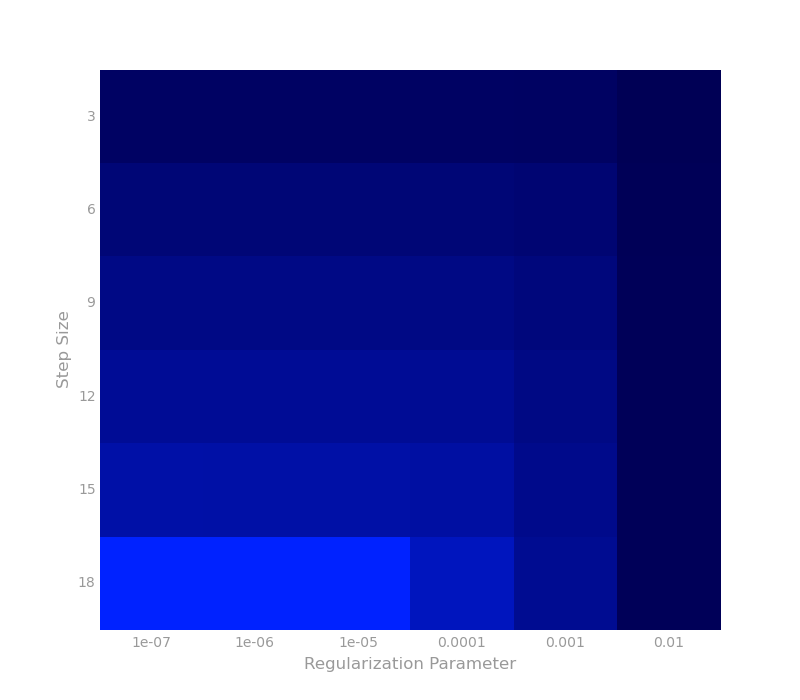
Fig 4. – Hyper-parameter tuning using grid search
References :
https://www.edx.org/course/scalable-machine-learning-uc-berkeleyx-cs190-1x
https://github.com/spark-mooc/mooc-setup/blob/master/ML_lab4_ctr_student.ipynb
https://labs.criteo.com/2014/02/kaggle-display-advertising-challenge-dataset/
|
Loic Le Bel Lead Software Developer, R&D Twitter: @loic_le_bel |
-
CriteoLabs

Our lovely Community Manager / Event Manager is updating you about what's happening at Criteo Labs.
See DevOps Engineer roles

