
The engine recommendation team
As we said time and again, performance is everything. The performance of our ads depends a lot on the content we put in them. We’ve found that personalized product selection makes for better ads: people tend to click more and buy more when we display content that’s tailored for them specifically. We’re able to gather a lot of browsing data on our merchant websites, and we have a fantastic prediction team focusing on scaling common regression algorithms for this volume of data. But we have billions of products and billions of users, so exploring the whole realm of display possibilities is untractable. Keeping the data up to date is also of paramount importance. Our merchants’ products change daily, and our users always visit new pages. So how can we display relevant ads taking into account information dating from several months as well as under a minute?

We can describe our problem as follows: given a user and the historical products he or she has interacted with on a merchant website, compute the N products to display to the user to maximize their purchases on the merchant website (with N~10). One of the standard textbook approaches for recommendation is through matrix factorization. Yet we did not implement this at Criteo for two main reasons: at-scale tractability and reactivity. We manage ads for thousands of clients, each of them having up to hundreds of millions of products. And we also have data for a few billion users, so any explicit representation of the User-Item matrix is doomed to fail at this level. Finally, we want to be able to take new events into account in a few seconds to always use the latest data about the user. To make the problem more tractable, we had to resort to simplifications by considering only a small subset of products.
Similarities between products
Products can be related because they have similar content (e.g. similar names) or because they target a similar audience. In particular, collaborative-filtering-based product similarities have long been used for new product discovery. For instance, widgets promoting “Users seeing this have also seen the following products”, or “Users seeing this ended up buying the following products”. Each of these product-pair relationships can be modeled as a product-to-product “similarity” matrix. Such similarity information can be extremely useful to model whether a particular product will interest a given user. Note that as product catalogs can be extremely big, these matrices cannot be stored explicitly. We thus resort to tricks such as sparse approximations to make the usage of the data tractable and build product similarity lists.

Fig. 2: A few similar items according to collaborative filtering.
Scaling properly: Product Sources Precomputation
As we can’t score every possible product for every single request, we need to generate a subset of products to score: the candidate products. We represent each user as the set of the products they interacted with and at request time, we look up the similarity list for each product they visited. We also use some non-product-specific product lists, e.g. the most purchased products or the most viewed products. The concatenation of all lists then provides the set of products we will score.
The nice thing about these candidate product lists is that they are user-agnostic. The link between products is fairly static and changes only slightly between two consecutive days. But if a user visits a new product and we display an ad a few seconds afterwards, we will be able to look up the candidate products for the new item instantly. This allows us to use even the freshest data to personalize the display.
The precomputation step to generate candidates is done using Hadoop MapReduce and Apache Spark on top of a YARN cluster. This allows us to recompute the candidate lists for billions of products several times per day, using millions of different features that are computed and fed directly into our prediction engine. We then push the candidate lists to a key-value couchbase storage that can be accessed for live ad requests.
Serving User Requests
When receiving a request, the recommendation service first fetches a few dozen candidate products in Couchbase. It then estimates the performance of each product for the current request using the in-house built regression engine. To that end, we train regression models on a dataset consisting of all the products we’ve displayed in the past, labeled with the interactions the user then had with the ad (e.g. clicks) and the merchant (e.g. purchases). We then pick the top products according to this metric and display them. Now, as the number of distinct products is extremely large, advanced feature engineering is key to making the best of the training data: most of our features focus on metadata that allow for good generalization across products and merchants.
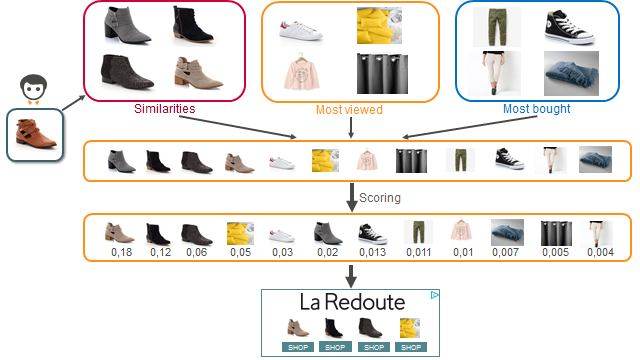
Fig. 3: User request workflow.
The recommendation service relies heavily on local in-memory caches when possible and uses asynchronous I/O when the data has to be fetched over the network. This cuts our hardware footprint while keeping latency low: a single server manages thousands of requests per second and can compute recommendations for a given request in around 10 ms.
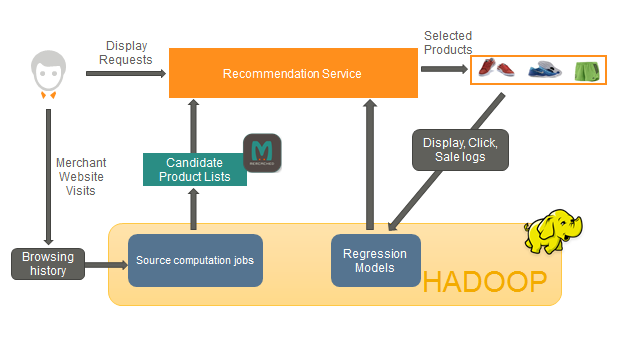
Fig. 4: General architecture diagram
Looking ahead
Of course, this design is a work in progress, and we’re working on many ways to improve our recommendation engine. We have projects covering every aspect piece of our infrastructure, from the distributed computing jobs to the online recommendation service. Of course, we spend a lot of time on feature work, trying to improve our models using more data. That’s not all: right now we’re working on more advanced modeling of the products and their metadata, which entails both NLP and computer vision aspects. We’re also working on modeling users using neural networks in order to better detect the user intent and where the user is at in her purchase cycle. Last, but not least, we have infrastructure constraints and we are working on making our code more efficient, which means we push our understanding of what happens deep under the hood of our machines. Challenges arise everywhere and always need work to make online advertisement more relevant. So check out our open positions and please shoot us an email if you want to be part of the adventure! We’ll also be there at ACM RecSys ’16 in Boston, so please meet us there for a chat or attend our talk.
-
Pierre - Emmanuel Mazaré

Staff Developpement Lead, Engine Recommendation
See Dev Lead roles

