
When people ask me what my job is, I never really know how to answer and usually say something along the lines “I try to keep computers working”. We are sometimes named DevOps, sometimes SRE, and honestly none of of us is really doing the same thing day to day, but we have one single goal in common: keep the system running.

Computer Problems
Providing a service
The “SRE” Departement at Criteo is divided in multiple sub-teams, each one in chargement of a particular perimeter and providing a service around it. This goes from taking care of the biggest HADOOP cluster in Europe to ensuring that continuous integration provide instant feedback to our developers.
The important part is that each team provides a service to internal users, for example one team can provide a NoSQL Database service: internal users will simply ask for a new database of a specific size to be created and the NoSQL team will ensure that this database is always available, performant, and up to date. These guarantees are part of a Service Level Agreement between the SRE Team and its users, kind of like what Amazon does.
Observability / Automation / Reliability
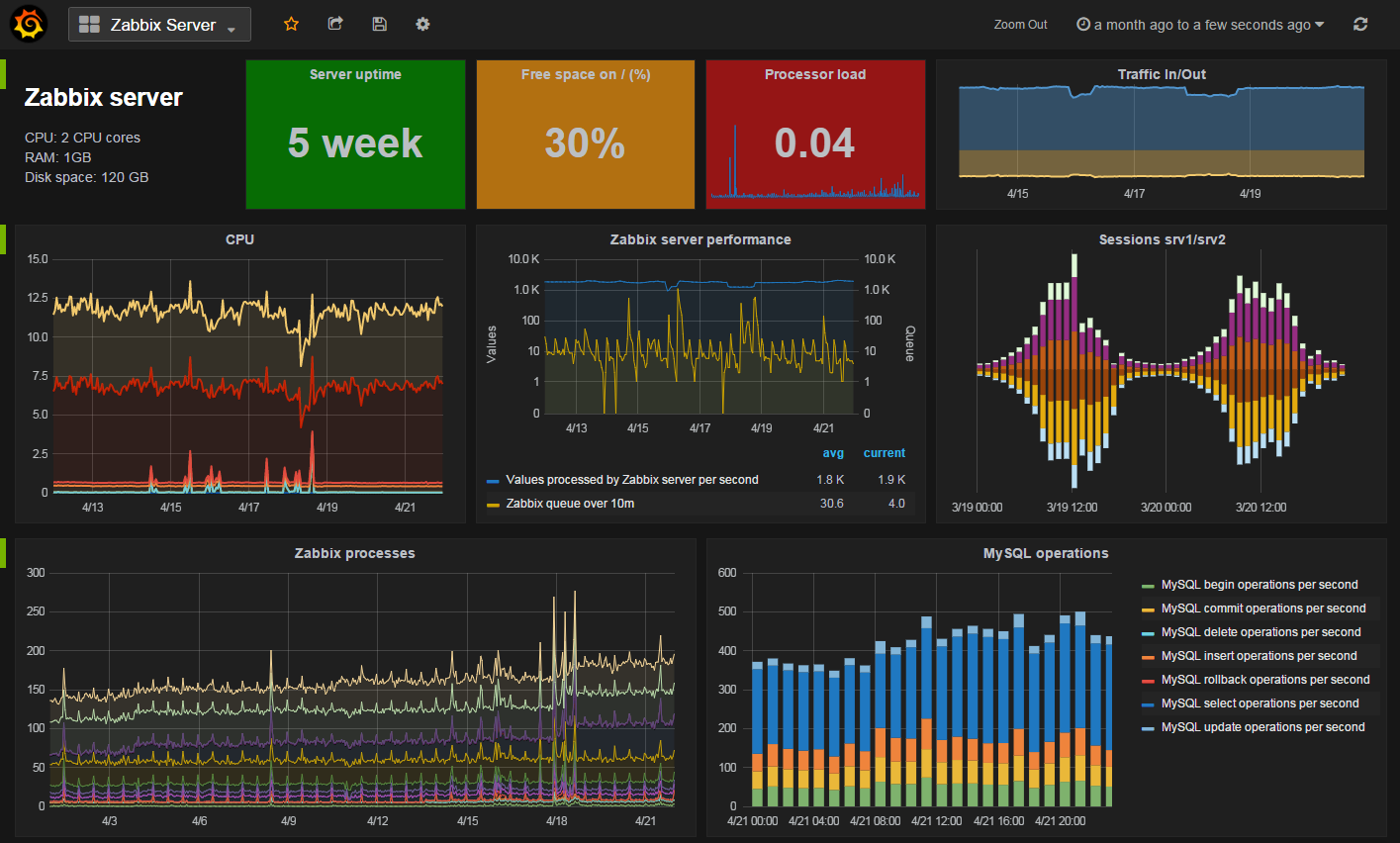
Observability is the ability to understand a system behavior from its outputs. It’s very important for us to have observable systems if we want to be sure that everything is working as it should, and be notified when it’s not ! We spend a good part of our time adding instrumentation to the software we run and creating probes. For example the team in charge of Graphite created a small program named metricroulette what sends points every second and measure how long it takes for them to be written in the database and be notified when they take too much time ! Internally, we use a variety of solutions to achieve that, including Graphite, Grafana, Prometheus, Kibana…

Automation
We have plenty of things to do, and our number of machines is increasing exponentially, there is simply no way to do everything manually (also it would be boring). Automation is super important for us, and we often ask ourselves “ Is it worth the time ?”. This can be by writing a simple shell script or even developing a long-running daemon that takes care of repetitive tasks for us. Weekly we try to look back at what we did and decide what should be automated away.
With the growing number of machines, reliability also becomes critical. Criteo has tens of thousands of servers, and we can’t allow everything to shutdown every time a single machine is broken: we get tens of broken machines per day ! This forces to design resilient architecture, our goal is to make everything at least N+2. The idea is that even when one machine (or one cluster !) is in planned maintenance you still want to have room for an “unplanned” maintenance. Our most advanced systems even undergo regular disaster recovery simulation where we intentionally break part of our productions systems to validate that the system as a whole will keep running.
Being on-call and communicating
An important part of our mission is to be on-call. The on-call person is responsible for making sure that her services are well behaving and will take appropriate action if they are not. During an incident one has to evaluate the impact, communicate it to other teams and apply the appropriate fixes.
But that doesn’t end here ! We would hate for the same incidents to occur again and again, which is why we systematically do post-mortems for important incidents. This include root cause analysis which will allow us to find part of the systems that, if changed accordingly, will prevent similar events to happen.
You can code, just do it !
Some would think: “So, humm, you’re a sysadmin right ?”. Well, no really, we need to be able to do everything. If a system doesn’t work as we need to then we will simply patch it ! We’ve sent patches to a lot of software that we use, including Graphite, Grafana, Consul, Prometheus, Cassandra, Chef, etc.. We even create our own software when needed, such as BigGraphite, a Cassandra plugin for Graphite. We code in a wide variety of languages, including Java, Python, Ruby, Go and others.
Interested ?
If you feel you’re fit for the job, we’re currently recruiting. Please look and apply here.
Comics courtersy of XKCD (https://xkcd.com/license.html)




