
Introduction
Prerequisite: A basic understanding of Spark big-data processing framework.
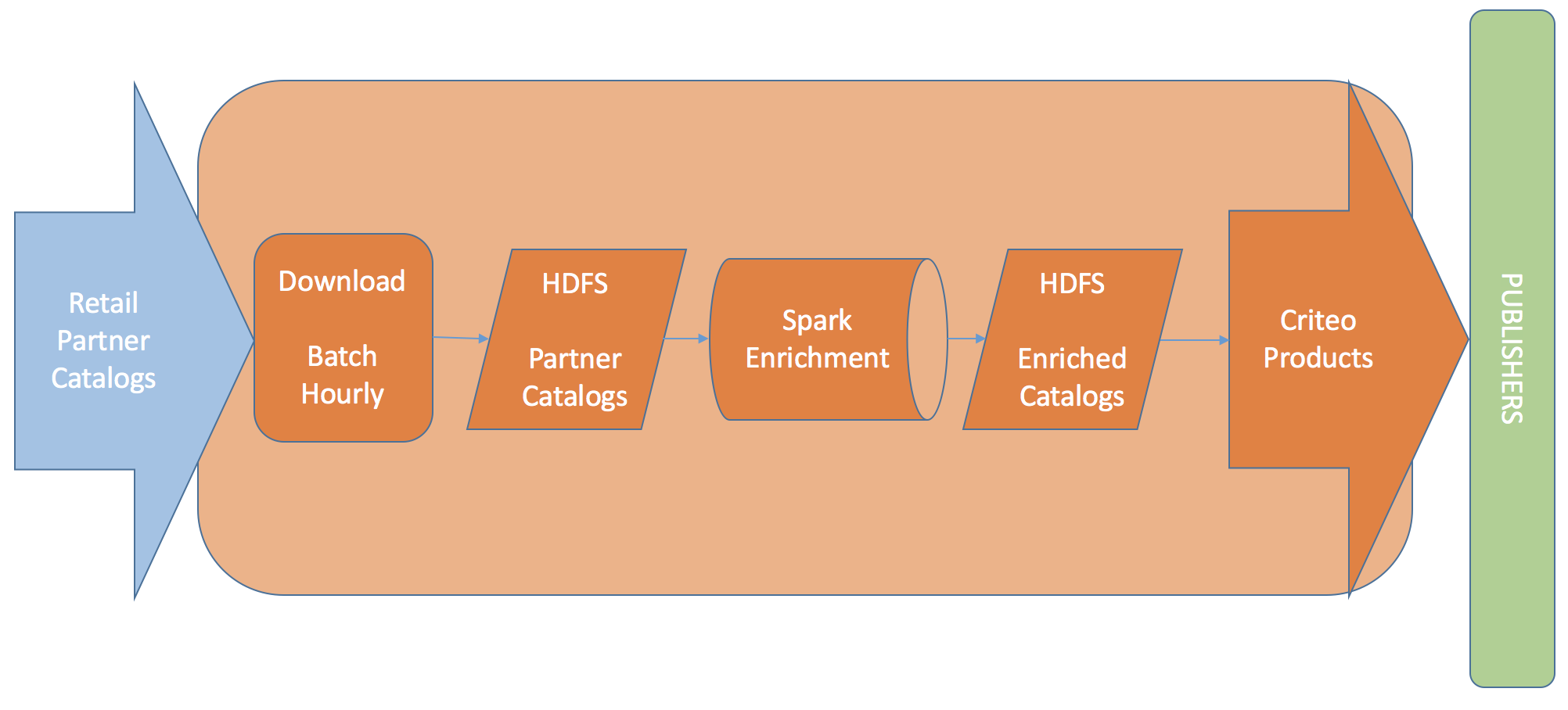
Criteo strategically places our retail partner’s product ads on publishers like CNN and NyTimes. Criteo Products make this possible by using internally enriched versions of catalog products from our retail advertisers(partners). Enrichment workflow utilizes ML to provide additional insights into our partners’ product catalogs by
- Categorizing products into Google’s product taxonomy categories. e.g. ascertain that Product A from Walmart and Product B from Sears are both Smartphones.
- Adding extra brand fields by identifying product’s brand from title and description. e.g. ascertain that Product A from Walmart and Product B from Sears are both a Samsung.
- Clustering similar products together to improve upon recommendation/attribution. (Enrichment workflow only assigns unique ID to similar products. Identification of similar products is done by a separate job). e.g. Find that Product A from Walmart and Product B from Sears are both a ‘Samsung Galaxy S8 – Midnight – Unlocked – 64 GB’
Problem Definition
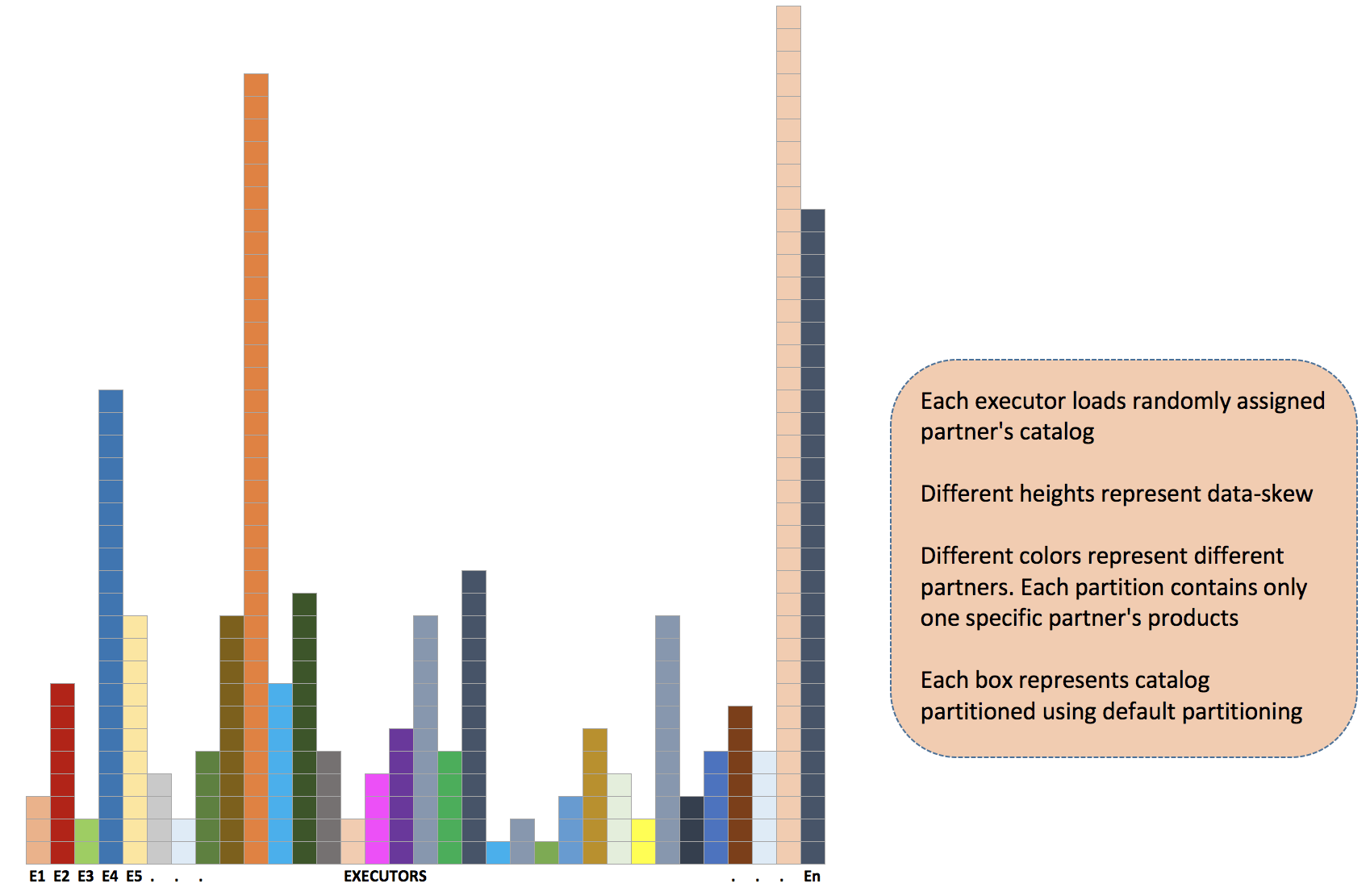
Data-Skew: We enrich partner catalogs in hourly batches. Partner’s catalog sizes vary substantially. Depending on the batch hour the number of catalogs and their sizes can be really different. Without shuffling skewed data, some executors will take longer to complete and thereby wasting premium executor resources.
Output Grouped-By partner: An easier problem in distributed-system is to load data, no-criteria balancing among executors and no-criteria sink’ing the output. But, we have to sink the data grouped-by partner. We used PairRddFunctions.saveAsHadoopFile with org.apache.hadoop.mapred.lib.MultipleTextOutputFormat to achieve this.
Partner Specific Model (Future): At present, we have a single ML model(~500MB) to predict product categories for all partners. This could change in future to geographical-market or partner specific ML model. In anticipation of this, we would like to keep partitions segregated by partners.
Shuffle
While loading zipped catalogs from HDFS, Spark partitions RDDs automatically without programmer intervention. Following diagram visualized the data-skew problem we are facing. Spark uses the default HashPartitioner to derive the partitioning scheme and also how many partitions to create.
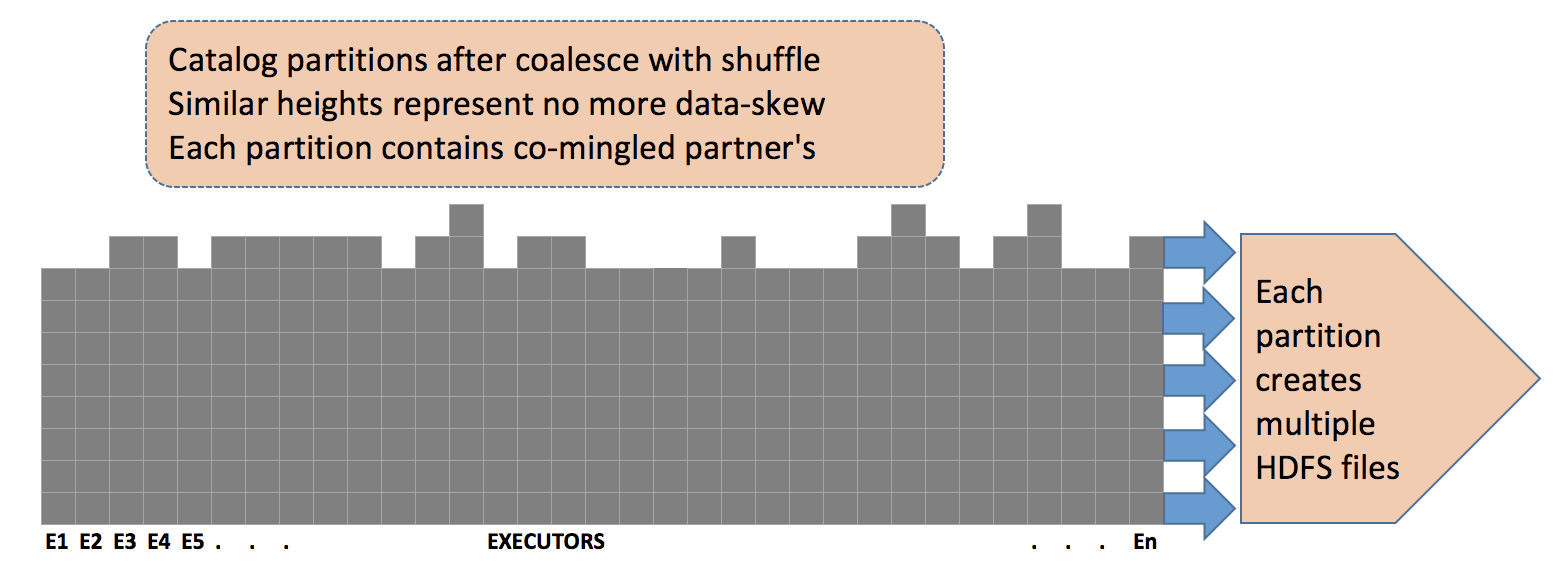
Using coalesce-with-shuffle to balance the catalogs across executors did solve the data-skew problem. But, since the data was shuffled without any criteria, the partitions were not segregated by partner anymore. It also posed a challenge to write enriched catalogs grouped-by partner. For N partition containing M (avg) partners’ products, the job will try to create N*M files on HDFS. The process never completed in a reasonable time. Not to mention, the file sizes were very small. Something that HDFS and ‘cluster-police’ will not be happy about.
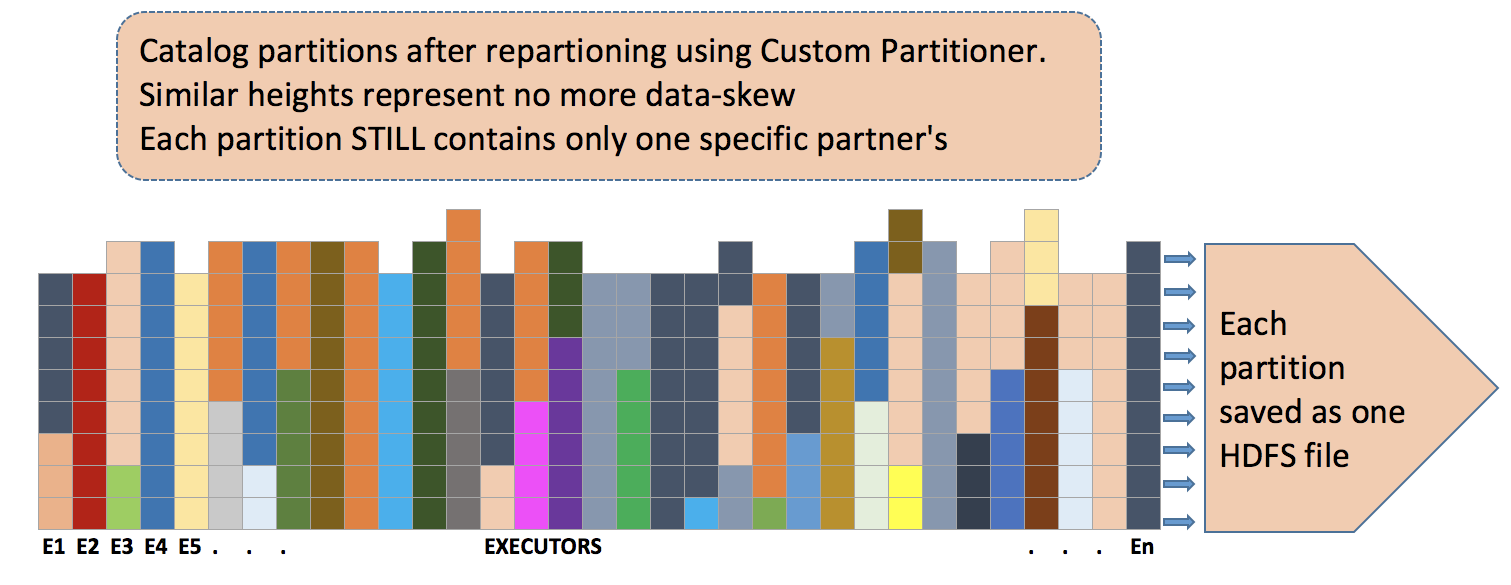
Custom Partitioner
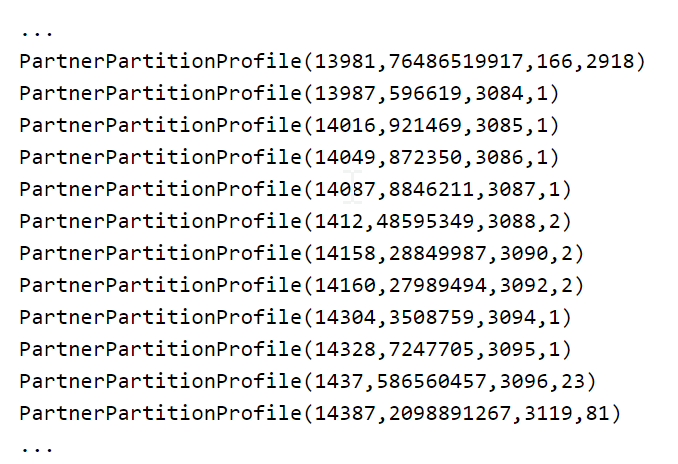
Custom partitioning provides a mechanism to adjust the size and number of partitions or the partitioning scheme according to the needs of your application. For Custom Partitioning, before loading data we create partner data profile based on the HDFS directory size using following data structure. We also use this profile to assign proportional number of executors to the Spark application.

A configurable partition size (currently 50-75MB) of unzipped products dictates the NoOfPartitions. Here is an example partition profile.
Next, we use PartnerPartitionProfile to proved Spark the criteria to custom-partition the RDD. We use partnerId and hashedExternalId (unique in the partner namespace) to assign a product to a partition.

Once the catalog batches are loaded, deserialized into Java Object and key’ed by (partnerId, hashedExternalId) we custom-partition them using the PartnerPartitioner.

Ending Notes
This problem was part of a migration from MapReduce to Spark framework. To read about other challenges we faced please follow following links.
Blog Post: Intra-Executor Shared Variables
Spark properties are like a cockpit. It provides a lot of knobs to choose the optimal configuration for your workloads. Once you get over being overwhelmed by the properties, you will love the control you have over cluster resources. For our workloads Spark runs 2x-3x faster with only 20% of the cluster resources needed by MapReduce.
I wanted to thank Anthony Truchet for providing valuable guidance through the whole project and also reviewing the blogs.
If you felt excited while reading this post, good news we are hiring! Take a look at our job postings.
Post written by :
 |
| Pravin Boddu Senior Software Engineer – Palo Alto |
-
CriteoLabs

Our lovely Community Manager / Event Manager is updating you about what's happening at Criteo Labs.
See DevOps Engineer roles

